”Haluan ostaa asunnon, joka olisi hyväkuntoinen ja sijainti on keskeinen, mutta asuinalueen pitäisi olla rauhallinen. Hinnan pitäisi myös olla edullinen.”
”Perheellemme pitäisi löytää lomakohde, josta löytyy mielenkiintoista tekemista isälle, äidille ja lapsille. Reissu ei saisi olla kuitenkaan kohtuuttoman kallis.”
”Haluan sijoittaa rahani niin että varallisuuteni kasvaisi mahdollisimman suureksi, mutta rahan häviämisen riski olisi mahdollisimman pieni.”
Yllä olevat kommentit kuvaavat erilaisia valintatilanteita, missä on useampi kuin yksi tavoite. Lisäksi tavoitteet ovat ainakin osittain ristiriitaisia. Tämä tarkoittaa sitä ettei ole olemassa sellaista ratkaisua, joka olisi optimaalinen kaikkien tavoitteiden suhteen. Joudumme siis etsimään kompromisseja.
Kompromissiloma
Toisessa kommentissa isän unelmaloma voisi olla Valioliiga-ottelun näkeminen Liverpoolissa, äidin surffausloma Balilla ja lapset haluaisivat Disney Worldiin. Kompromissivalinta voisi olla esimerkiksi Malaga, missä pääsee katsomaan Espanjan jalkapalloliigaa, löytyy merenranta surffaukseen (vaikkei aallot vastaakaan Balia) sekä vesipuisto lapsille. Jokaisen perheenjäsenen tavoitteessa jouduttiin hieman antamaan periksi. Silti valinta tyydyttää kaikkia ja budjetti on vanhemmille miellyttävämpi kuin Euroopan ulkopuolisissa kohteissa. Tämän tyyppisiä valintatilanteissa turvaudutaan monitavoitteiseen (tai monikriteeriseen) päätöksentekoon.

Varaston optimointia
Sen kunniaksi että ikuisuusprojektin viittaa kantanut toinen väitöskirjaani tuleva artikkeli vihdoin syksyllä julkaistiin, käyn tässä läpi monitavoiteoptimointia artikkelissa olevan sovelluskohteen näkökulmasta. Kyseessä on yrityksen varaston optimointiongelma: päätöksentekijänä on ostopäällikkö, jonka pitää päättää kuinka paljon tilataan varastoon alihankkijalta tavaraa, jonka toimitusaika on 3 kk. Kyseessä oli teollisuusyritys ja tilattava tavara oli kallis komponentti, jota tarvitaan lopputuotteen valmistamiseen. Matematiikka kuitenkin täsmää vaikka tavara olisi tukkukauppiaalta tilattava valmis tuote jälleenmyytäväksi.
Yrityksen ostotoimintoihin ja varaston ylläpitöön liittyy useita kustannuksia. Esimerkiksi kuljetuskustannukset, pääomakustannukset (yrityksen varoja sitoutuu varaston tuotteisiin) ja tuotteiden vanheneminen/pilaantuminen. Mikäli ostopäällikkö pelkästään minimoisi kustannuksiaan, hänen ei koskaan kannattaisi tilata mitään. Ikävänä sivuseurauksena silloin yrityksen liiketoimintakin loppuisi kun ei ole mitään myytävää.
Ostopäällikon ongelma on siis seuraava:
– jos hän tilaa usein / paljon tavaraa varastoon, kustannukset nousevat pilviin
– jos hän tilaa liian vähän, kaikille asiakkaille ei riitä lopputuotetta myytäväksi.

Eräs ratkaisu on arvioida, mikä kustannus yritykselle tulee yhdestä pettyneestä asiakkaasta ja lisätä tämä muihin varastointikustannuksiin, jolloin tilauspäätös voitaisiin tehdä kaikkia näitä kustannuksia minimoimalla. Nyt oleellisia kysymyksiä ovat:
– Kuinka paljon yksi pettynyt asiakas pitkällä tähtäimellä maksaa?
– Onko yrityksen brändiarvon heikkeneminen lineaarista vai onko 5:n peräkkäisen pettymyksen hinta suurempi kuin 5 kertaa yksi pettymys?
Sen sijaan että ravistelee hihasta euromääräisen hinnan asiakkaan pettymykselle, on mahdollista mitata ajallaan palveltujen asiakkaiden määrää omalla mitta-asteikollaan. Eli ei yritäkään muuttaa asiakkaiden kokemia pettymyksiä Euroiksi. Tästä pääsemmekin monitavoiteoptimoinnin maailmaan.
Kahden tavoitteen optimointi yhtäaikaa
Nyt meillä on päätöksenteolle kaksi tavoitetta:
1. varastointikustannusten minimointi
2. asiakkaiden palvelutason maksimointi
Nämä ovat ristiriitaisia tavoitteita, koska ensimmäisen tavoitteen kannalta pitäisi tilata varastoon mahdollisimman vähän ja toisen kannalta mahdollisimman paljon. Sopivan kompromissin löytämisen avuksi tulee käsite Pareto-optimaalisuus.
Tutkimuksessa ostopäällikön ostostrategiassa käsiteltiin kolmea aikapistettä yhtäaikaa: kuinka paljon tilataan ensimmäisessä mahdollisessa erässä, kuinka paljon seuraavassa ja kuinka paljon sen seuraavassa. Yhden eräkoon vaihdellessa välillä 0-250 kpl, mahdollisia kombinaatioita on 251^3 = 15813251 kpl. Otetaan tässä kuitenkin käsittelyyn hieman yksinkertaistettu kuvitteellinen esimerkki, missä eräkoko voi vaihdella välillä 0-9, jolloin kombinaatioita on ”vain” 1000 kpl. Ne on kuvattu pisteinä alla olevassa koordinaatiossa. Tässä esimerkissä oletetaan 100€ kiinteä kuljetus- ja käsittelykustannus aina kun tilataan nollaa suurempi erä.
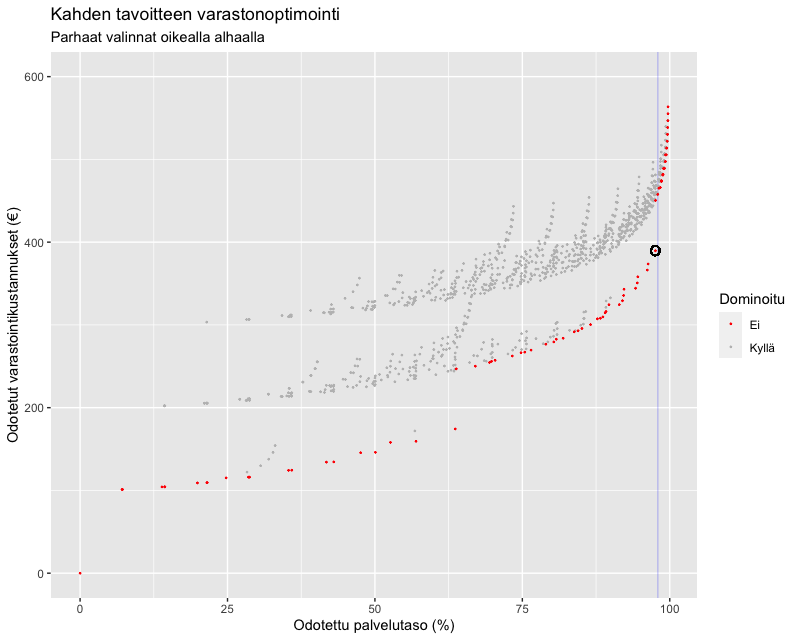
Kuvaajassa vaaka-akselilla on odotettu palvelutaso (kuinka suuri %-osuus kysynnästä saadaan ajallaan tyydytettyä) ja pystyakselilla odotetut kustannukset eri tilausmäärä-valinnoilla. Hyvät vaihtoehdot sijaitsevat alhaalla oikealla, mutta mikä valinnoista on paras? Tähän ei ole yksiselitteistä vastausta, mutta sen sijaan me osaamme sanoa, mitkä eivät ainakaan ole parhaita. ”Harmaiden pisteiden sanotaan olevan dominoituja, koska yhden tavoitteen parantamiseksi ei toisesta tavoitteesta tarvitse tinkiä.”
Sen sijaan punaisia pisteitä ei ole dominoitu. Mikäli punaista ratkaisua haluaa parantaa yhdessä tavoitteessa, on pakko heikentää toista tavoitetta. Näitä punaisia ratkaisuja sanotaan Pareto-optimaalisiksi. Ostopäällikön tehtäväksi jää näistä Pareto-optimaalisten ratkaisujen joukosta löytää näkemystään hyödyntäen sopivin kompromissi.
Jos viime aikoina on usealle asiakkaalle jouduttu myymään ”ei oota” ostopäällikkö saattaisi nyt pelata varman päälle ja tavoitella lähelle 100% olevaa palvelutasoa. Lopullinen valinta voisi olla ympyröity piste. Tällä valinnalla odotettavissa on 97.6% palvelutaso (vaaka-akseli) ja 390 euron (pystyakseli) varastointikustannukset. Siihen päästään kun tilataan varastoon ensimmäisessä erässä 9, toisessa 9 ja kolmannessa 0 tuotetta.
Tämä esimerkki kuvaa myös eroa monitavoiteoptimoinnin ja rajoitetun optimoinnin välillä. Mikäli ostopäällikkö olisi määrittänyt rajoitteeksi 98% palvelutason (sininen pystyviiva) ja minimoinut sitten pelkästään kuluja, hän olisi päätynyt pystyviivan oikealla puolella olevaan ratkaisuun. Siten hän ei olisi koskaan saanut tietää että vain 0.04%-yks. pudotuksella 98% tavoitteesta pystyi saamaan merkittävän n. 70€ säästön. Tätä säästöä selittää 100€ säästö kuljetus- ja käsittelykutannuksissa kun kolmas tilauserä jätetään nollaksi.
Ratkaisujen laskeminen
Kun mahdollisia päätöksiä (tai päätöskombinaatioita) on miljoonia tai jatkuvien muuttujien tapauksessa rajaton määrä, kaikkien mahdollisten ratkaisujen laskeminen veisi aivan liian paljon aikaa myös nopeimmilta tietokoneilta. Niinpä on kehitetty laskenta-algoritmeja, jotka etsivät pelkästään Pareto-optimaalisia ratkaisuja päätöksentekijän toiveiden mukaisesti. Algoritmeja on paljon erilaisia erilaisiin sovelluksiin, mutta tunnetuin yleiskäyttöinen algoritmi lienee NSGA (Non-dominated Sorting Genetic Algorithm).
Vielä lisää tavotteita
Tavoitteiden määrä ei välttämättä rajoitu kahteen. Tutkimuksessa ostopäälliköllä oli vielä kolmaskin tavoite: varaston kiertonopeus (=kuinka usein tavara vaihtuu varastossa). Vaikka kiertonopeus korreloikin varastointikustannuksen kanssa, se tuo tärkeää lisäinformaatiota ostopäällikölle. Mikäli kiinteät kuljetus- ja käsittelykustannukset ovat korkeat, kustannusten minimointi suosii isoja kertatilauksia. Isot tilausmäärät kuitenkin pienentävät varaston kiertonopeutta tuottaen käytännön ongelmia varastotilojen riittävyyteen, varastotyöntekijöiden työturvallisuuteen ja nostavat riskiä että tuotteet vanhenevat varastoon.
Vaikka kolmen tavoitteen pohjalta muodostettu Pareto-optimaalisten ratkaisujen joukko on hankalampaa (ja neljän tavoiteen mahdoton) visualisoida koordinaatistossa, monitavoiteoptimointialgoritmit kyllä hoitavat Pareto-optimaalisten ratkaisujen etsimisen samoin kuin kahden tavoitteen tapauksessa.
Kysynnän ennustaminen
Päätöksentekijällä on vielä yksi ongelma. Tavoitteiden laskemiseen tarvitaan tietoa tulevien kuukausien kysynnästä lopputuotteelle, mutta yleensä tätä ei varmaksi tiedetä etukäteen. Sen sijaan historiadatan avulla pystymme arvioimaan todennäköisyyksiä erilaisille kysyntäskenaarioille. Tähän sukellamme tarkemmin jossain toisessa blogikirjoituksessa, mutta mikäli asia kiinnostaa voit tutustua tähän kaikkeen lukemalla itse artikkelin. Virallinen julkaisu löytyy maksumuurin takaa täältä, mutta yliopistolla on myös ilmainen rinnakkaisjulkaisu vähemmän viimeistellystä versiosta, joka löytyy täältä.
Yhteenveto
Yksi tapa kuvata monitavoitteista päätöksentekoprosessia on Daniel Kahnemanin populariosoiman kahden ajattelusysteemin (lue esittely esim. täältä) yhdistäminen. Ensiksi käytetään hidasta, eli 2-systeemin, ajattelua määrittelemällä päätökseen hyvyyteen vaikuttavat tavoitteet. Laskenta-algoritmeja hyödyntämällä näiden tavoitteiden perusteella karsitaan huonot vaihtoehdot pois. Jäljelle jääneistä Pareto-optimaalisista vaihtoehdoista tehdään lopullinen valinta nopeaa, eli 1-systeemin, ajattelua hyödyntäen. Näin saadaan sulavasti tietokoneen laskentateho sekä ihmisen näkemys ja intuitio tekemään yhteistyötä tilanteeseen sopivan kompromissin etsimisessä.



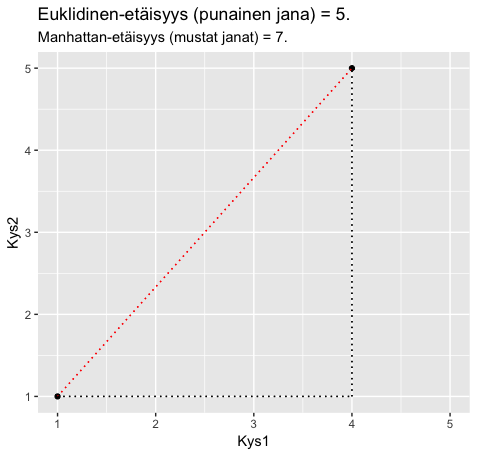
 . Eli kaikista janoista muodostuvan kolmion kateettien neliöiden summa on sama kuin hypotenuusan neliö. Geometrisessa tulkinnassa on kuitekin muistettava, että siinä täytyy olettaa vastausvaihtoehtojen välimatkat yhtä pitkiksi. Eli esimerkiksi ero ”Täysin eri mieltä” ja ”Jokseenkin erimieltä” välillä on sama kuin ”En osaa sanoa” ja ”Jokseenkin samaa mieltä” välillä.
. Eli kaikista janoista muodostuvan kolmion kateettien neliöiden summa on sama kuin hypotenuusan neliö. Geometrisessa tulkinnassa on kuitekin muistettava, että siinä täytyy olettaa vastausvaihtoehtojen välimatkat yhtä pitkiksi. Eli esimerkiksi ero ”Täysin eri mieltä” ja ”Jokseenkin erimieltä” välillä on sama kuin ”En osaa sanoa” ja ”Jokseenkin samaa mieltä” välillä.