
Sosiaalisten medioiden suosittelualgoritmit sanotaan ajavan käyttäjiä syvemmälle omiin kupliinsa samanhenkisten ihmisten pariin. Mutta mitä se haittaa? Eikö se nimenomaan ole kiva, että ihmiset löytävät uutta samanhenkistä seuraa? Totta tämäkin puoli, mutta ongelma on, että “kuplautuminen” tekee meistä tyhmempiä.
Twitterkupla
Itse en ole vielä löytänyt tietäni Instaan/Tiktokkiin, joten lähestyn asiaa Twitterin näkökulmasta. Luultavasti samat ajatukset sopivat kyllä myös muihin medioihin. Oma Twitter-kuplani muodostuu pääasiassa tilastotieteilijöistä, vedonlyöjistä, sijoittajista ja taloustieteilijöistä. Tätä kautta saan paljon itselleni hyödyllistä informaatiota, mutta kuplani kattaa lopulta aika rajoittuneen kirjon ihmiselämän osa-alueista.
Keskenään korreloivat asiantuntijat
Robertit Clemen ja Winkler julkaisivat jo vuonna 1985 mielenkiintoisen tutkimuksen erilaisten taustojen omaavien ihmisten tarjoaman informaation arvosta, vaikka laajassa käytössä oleva internet oli vasta pilke koodareiden silmäkulmassa. Tausta-ajatuksena ja oletuksena on että erilaiset asiantuntijat tarjoavat ennusteita jostain tulevasta tapahtumasta (esim. työttömyysasteen muutos ensi vuonna) ja nämä ennusteet noudattavat k-ulotteista normaalijakaumaa, missä k tarkoittaa asiantuntijoiden lukumäärää.
Oleellinen asia on, että saman kuplan sisällä ihmisten näkemykset korreloivat voimakkaasti. Näin ollen toinen asiantuntija saman kuplan sisällä ei enää tarjoa yhtä paljon infoa kuin ensimmäinen. Informaation arvo romahtaa yllättävän voimakkaasti korrelaation kasvaessa. Otan esimerkiksi sijoitusvihjeen. Huomaan, että lyhyen ajan sisällä 5 eri pätevänä pitämääni sijoittajaa ilmoittaa Twitterissä ostaneensa yhtiön Z osaketta. Tällaisessa tilanteessa olen joskus tehnyt itsekin perässä sijoituksen hyvin kevyellä omalla perehtymisellä. “Jos 5 eri itseäni kokeneempaa sijoittajaa näkee yhtiön hyvänä sijoituskohteena, ei sijoitus voi pahasti metsään mennä.” Tässä kohtaa pitäisi kuitenkin pohtia esim:
– Seuraavatko nämä 5 sijoittajaa toisiaan Twitterissä?
– Perustavatkohan he sijoituspäätöksiään samoihin analyysiraportteihin?
Molemmat kasvattavat heidän näkemystensä välistä korrelaatiota. Alla on kuvaaja, missä X akseli kertoo asiantuntijoiden välisen korrelaatiokertoimen (kaikki parittaiset korrelaatiot oletetaan samoiksi) ja Y-akseli kertoo kuinka monen yksittäin yhtä pätevän, mutta keskenään riippumattoman, asiantuntijan tietomäärää kyseisten viiden kuplautuneen asiantuntijan ennusteen tietomäärä vastaa. Kuvaajasta nähdään esimerkiksi: “Viiden asiantuntijan, joiden välinen korrelaatio on 0.375, ennusteen informaation määrä vastaa kahta riippumatonta, mutta muuten vastaavaa asiantuntijaa.”
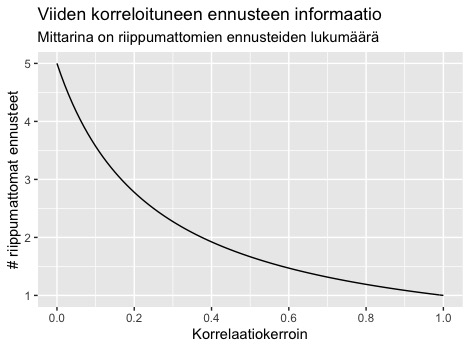
Tutkimuksessa osoitetaan myös yläräja vastaavan riippumattoman asiantuntijan määrälle kun kuplan sisällä oletetaan kaikki parittaiset korrelaatiot samoiksi. Se on 1/korrelaatio. Eli jos kuplan sisäinen korrelaatio on 0.5, haastattelemalla kaikki kuplan jäsenet ei voida saada hyödyllisempää ennustetta kuin kahdelta (1 / 0.5 = 2) vastaavalta toisistaan riippumattomalta asiantuntijalta. Eli vaikka kuplassa olisi satoja jäseniä, heidän yhdessä tarjoaman ennusteen informaation määrä vastaa korkeintaan kahta riippumatonta (mutta yksittäin yhtä tarkkaa) asiantuntijaa.
Edellisissä laskelmissa käytettävät oletukset ovat toki hyvin karkeita yksinkertaistuksia, mutta artikkelissa johdetaan kaavoja myös hieman realistisempiin tilanteisiin, missä kaikkien asiantuntijoiden ennusteet eivät ole yhtä tarkkoja (siellä käsitellään myös vaihtelevien korrelaatioiden tapaus, vaikken sitä tässä tekstissä käsittele). Oletetaan, että omassa kuplassasi on kaikki parhaat asiantuntijat, joiden ennusteet ovat maailman tarkimpia. Toisessa kuplassa olisi myös eräs asiantuntija, mutta hänen arviot ovat 1.5 kertaa epätarkempia kuin oman kuplasi “huippuasiantuntijoiden”. Täsmällisemmin, toisen kuplan asiantuntijan ennusteiden keskihajonta on 1.5-kertainen. Saadaan lasketuksi, että mikäli omassa kuplassasi korrelaatiokerroin on 0.5, yhden oman kuplasi jäsenen ja toisen epätarkemman, mutta riippumattoman asiantuntijan muodostama, ennuste on tarkempi kuin kahden oman kuplasi “huippuasiantuntijan” muodostama yhdistetty ennuste.
Oman kuplani venytys
Eräs esimerkki omasta kuplani venyttämisestä on ollut sosiologi-kansanedustaja Anna Kontulan seuraaminen Twitterissä, vaikka aluksi hänen positiiviset ajatukset kommunismia kohtaan hieman jännittivätkin. Vieläkään minusta ei ole tullut kommunistia muualla kuin perheen ja läheisten ystävien parissa, mutta moneen ajankohtaiseen asiaan häneltä on tullut hyviä näkökulmia, mitkä ovat jääneet muilta Twitter-kuplassani huomaamatta. Pidän Annasta erityisesti siksi, että hän keskustelee rakentavaan sävyyn myös täysin eri mieltä olevien ihmisten kanssa. Tämän kokemuksen perusteella kannustan muitakin etsimään uusia seurattavia sellaisista ihmisistä ketkä kannattavat asioita, mitkä aiheuttavat nyt vielä nenän nyrpistystä. Ne arvokkaimmat tiedonlähteet löytyvät todennäköisesti juuri tästä porukasta. Toki syytä on rajoittua vain erilaisia ihmisiä ja mielipiteitä kunnioittaviin henkilöihin. Jatkuvaa negatiivista räksytystä en kehoita kuuntelemaan.
Kommunismista
Lopuksi vielä muutama sananen siitä, mitä olen oppinut kommunismista viimeaikoina luettuani Anna Kontulan kirjoituksia, erityisesti tämän blogipostauksen.
Ensiksi täytyy todeta, että olen eri mieltä kirjoituksen ensimmäisestä listatusta taustaoletuksesta. Eli siitä että (ainakaan nykyään) työn ja pääoman välillä olisi jokin ristiriita. Mielestäni molemmat nimenomaan tarvitsevat toisiaan. Mitä isommasta ja useaa eri osaamista vaativasta projektista on kyse, sitä tärkeämpi rooli arvon muodostuksessa on duunareiden työn lisäksi sillä, että joku sijoittaja (tai joukko sijoittajia) on valmis ottamaan vastuun kokonaisuuden organisoimisesta. Ottamaan riskiä ja maksamaan duunareille heti täsmällistä kuukausipalkkaa vaikka tuotot tulevat, jos tulevat, joskus kaukana tulevaisuudessa. Ilman kaikkia näitä palasia iso projekti jäisi duunareiden korkeasta erikoisosaamisesta huolimatta toteutumatta.
Annan kirjoitukset avasivat kuitenkin silmiä monelta osin. Olin aiemmin ajatellut, että kommunismi voi toimia vain hyvin pienissä porukoissa, missä kaikilla on vahva tunneside toisiinsa, esim. perheet. Hoksasin kuitenkin, että esimerkiksi koodareiden avoimen lähdekoodin kirjastojen jakamiseen tarkoitettu yhteisö GitHub toimii kommunismin tavoin, vaikka suurin osa muista koodareista ovat täysin tuntemattomia. Seuraava Annan kommentti on auttanut ajattelemaan kommunismia muunakin kun hirmuhallitsijoiden propagandana:
Kommunismi ei ole ratkaisu kaikkeen. Jokaiselle lienee jo tässä vaiheessa tekstiä selvää, että en usko minkään -ismin toimivan yleisenä ihmelääkkeenä, vaan että hyvään yhteiskuntaan pääseminen edellyttää oikeiden lääkkeiden valintaa kuhunkin tilanteeseen. Lisäksi monet aikamme ongelmat vaativat globaalia päätöksentekoa ja todennäköisesti myös globaalia sääntelyä. Kommunismi toimii parhaimmillaan yhteisöissä, joiden koko mahdollistaa jokaisen henkilökohtaisen osallistamisen tai joiden sitouttaminen perustuu ihmisten valintaan liittyä ja erota niistä esimerkiksi jonkin verkkoalustan tai yhdistyksen kautta. Kun päätöksenteko koskee miljoonia tai miljardeja, on käytettävä muita järjestäytymisen logiikoita.
Anna Kontula
Ajatusprosessi tästä teemasta on vielä kesken enkä varmaan ymmärrä vielä täysin, mitä kommunismiin perehtyneet täsmällisesti kommunismilla tarkoittavat. Tällä hetkellä ajattelen yhteistyön organisoimisesta seuraavasti:
– Pienissä yhteisöissä, missä kaikilla on yhdistävä tunneside toisiinsa, kommunismi on standardi järjestäytymisen muoto.
– Miljoonien ihmisten yhteiskunnissa, missä kaikki ihmiset eivät tunne toisiaan, “demokraattinen valtio + markkinatalous + kapitalismi” on standardi järjestäytymisen muoto.
Mutta mikäli jossain erityisessä tapauksessa joku toinen kuin se standardi tapa toimii paremmin, niin antaa mennä sit vaan. Esimerkiksi kun GitHubissa avoimen lähdekoodin kehitys toimii kommunismin periaatteella niin antaa palaa. Mutta silti lopullisten ohjelmistoratkaisujen toimittaminen ja ylläpito asiakkaalle todennäköisesti toimii parhaiten markkinataloudessa kilpailevien yritysten toimesta.
Eräs esimerkki toiseen suuntaan on edustamani futsal-joukkue Feeniksin toimitsijavuorot. Kun perustimme seuran reilu kymmenen vuotta sitten, meitä oli yksi joukkueellinen keskenään hyvin toisensa tuntevia kaveruksia. Toimitsijavuorot hoituivat kommunismin hengessä lähes itsestään: loukkaantunut pelaaja tai jonkun kaveri/tyttöystävä kävi aina homman talkoohengessä hoitamassa ilman sen isompia maanitteluja. Kun myöhemmin organisaatio laajeni kahden joukkueen ringiksi, ei kommunismi enää toiminut vaan toimitsijavuorot kaatuivat toistuvasti samojen muutaman seura-aktiivin niskaan. Onneksi markkinatalous pelasti seuramme ja toimitsijavuorolle löytyi rahallinen hinta, millä kiireisimmät pääsivät eroon toimitsijavuorovastuustaan ja ahkerat saivat palkkion käytetystä ajastaan alennettujen kausimaksujen muodossa.

Aika näyttää mihin ajatukseni yhteiskunnan optimaalisesta organisoimisesta kehittyy, mutta sen uskallan sanoa että olen nyt aiheesta huomattavasti viisaampi kuin ennen Twitter-kuplan laajentamista yhteen kommunistiin. Sopivasssa rajoitetussa ympäristössä kommunismi vaikuttaa olevan muutakin kuin diktaattoreiden propagandaa ja tyhjiä kaupan hyllyjä. Mutta vaikka samanhenkisten kommuunissa voikin olla parhaillaan kivaa kivaa, ei pidä unohtaa kommunikointia naapurikommuunien kanssa. Ettemme kuplissamme taantuisi tyhmemmiksi.









 .
. .
.






