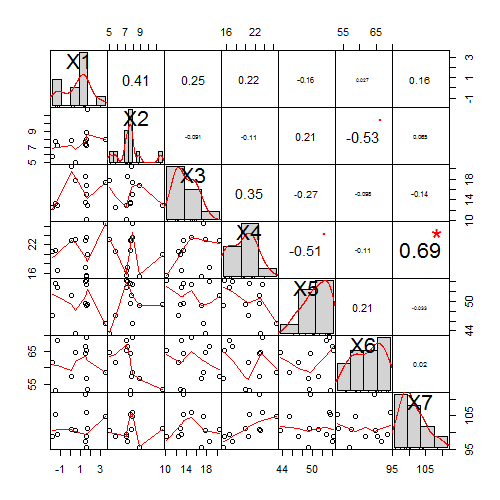
Vieläkö muistat, mikä yhteys on uima-altaaseen hukkumisella ja Nicholas Cagen elokuvaesiintymisillä? Vastaus on että eipä juuri mikään, mutta silti niiden välille on mahdollista havaita keskinäistä riippuvuussuhdetta mittaavaa korrelaatiota. Aiemmassa blogikirjoituksessa havainnollistin kuinka korrelaatioita pompsahtelee esiin vain sattumalta kun tarpeeksi montaa eri muuttujaparia kokeillaan. Seuraavassa pureudutaan yleiseen hämäävien korrelaatioiden lähteeseen; aikaan.
Vieläkö muistat, mikä yhteys on uima-altaaseen hukkumisella ja Nicholas Cagen elokuvaesiintymisillä? Vastaus on että eipä juuri mikään, mutta silti niiden välille on mahdollista havaita keskinäistä riippuvuussuhdetta mittaavaa korrelaatiota. Aiemmassa blogikirjoituksessa havainnollistin kuinka korrelaatioita pompsahtelee esiin vain sattumalta kun tarpeeksi montaa eri muuttujaparia kokeillaan. Seuraavassa pureudutaan yleiseen hämäävien korrelaatioiden lähteeseen; aikaan.
Korrelaatio ja aikatrendit
Otin Gapminder –datapankista tiedot Lapsikuolleisuudesta Kiinassa (alle 5v kuolevia per 1000 syntymää) ja Sähkön käytöstä Suomessa (kWh per asukas). Molemmista löytyi dataa vuosilta 1960-2011. Nämä ovat tarkoituksella haetut muuttujat, joilla ei pitäisi olla mitään tekemistä toistensa kanssa. Eihän meillä voi olla niin huono säkä, että data näyttäisi silti niiden välille korrelaatiota? Katsotaan muuttujien välistä sirontakuviota oikealla.

Suomen sähkönkulutuksen ja Kiinan lapsikuolleisuuden sirontakuvio
Vaikuttaisi kuitenkin siltä, että silloin kun Suomessa on korkea sähkönkulutus, niin Kiinassa lapsia kuolee vähemmän. Korrelaatiokerroinkin -0.84 vahvistaa saman: muuttujien välillä on vahva negatiivinen lineaarinen yhteys. Pitäisikö tästä nyt tulkita, että mikäli haluamme pelastaa kiinalaisia lapsia, niin pitää heti laittaa uuni ja sähkösauna päälle?
Tutkitaan seuraavaksi molempien muuttujien kehitystä ajassa erikseen.

Lapsikuolleisuuden ja sähkönkulutuksen aikatrendit
Nähdään, että Kiinan lapsikuolemissa on ollut selvä laskeva trendi ja suomalaisten sähkönkulutuksessa selvä nouseva trendi. Omituinen korrelaatio näiden muuttujien välillä ei selity tällä kertaa sattumalla vaan yhteisellä taustatekijällä, mikä on nyt aikatrendi. Koska trendit ovat erisuuntaiset, korrelaatiokerroin on negatiivinen.
Tutkitaan sitten alkuperäisten havaintojen sijaan muutoksia edelliseen aikapisteeseen verrattuna. Näin saadaan trendit eliminoitua havainnoista, kuten kuvaajista nähdään.

Muutosmuuttujien kehitys ajassa
Näiden muutosmuuttujien välille laskettu korrelaatiokerroin on -0.03. Tämä on niin lähellä nollaa että voimme turvallisesti sanoa ettei Suomen sähkönkulutuksen muutoksella ole mitään yhteyttä saman vuoden Kiinan lapsikuolleisuuden muutokseen. Varmistetaan asia vielä piirtämällä sirontakuvio ja havaitsemalla ettei yhteistä systematiikkaa löydy.

Muutosmuuttujien sirontakuvio
Autokorrelaatiot
Myöskään trendittömien muuttujien aikahavaintojen tutkiminen ei ole aivan yksinkertaista. Mikäli olemme kiinnostuneita epävarmuudesta ja korrelaation tilastollisesta merkitsevyydestä, usein päävaivaksi tulee autokorrelaatio. Tällä tarkoitetaan sitä että saman muuttujan peräkkäiset havainnot korreloivat keskenään. Perusmenetelmiin liittyvä oletus riippumattomasta satunnaisotoksesta ei nyt päde ja kahden autokorreloituneen muuttujan riippuvuuden tutkimiseen on parempi käyttää esim. vektoriaikasarja-malleja.
Tilastoja tutkimaan
Lopuksi pitää vielä kehua datapankkia, josta lapsikuolleisuus ja sähkönkulutusdatat ovat haettu. Sivustolta löytyy läjäpäin muutakin terveys-, talous- ja muuta yhteiskunnallista dataa ympäri maailmaa ja niitä voi kätevästi graafisesti tutkailla tällä sivustolla. Mutta pidäthän tämän blogin opetukset mielessä ennen kuin vedät johtopäätöksiä liittyen syy-seuraus suhteisiin. Lopuksi voi vielä viihdyttää itseään käymällä tsekkaamassa vanhaa sivua, jossa on koottuna huumorikorrelaatioita. Nyt pitäisi olla valmiudet perustellusti spekuloida jokaisen kuvaajan kohdalla, johtuuko korrelaatio
- jostain yhteisestä taustamuuttujasta
- aikatrendistä
- sattumasta
- aidosta riippuvuussuhteesta
- vai jostain edellisten yhdistelmästä.
Statistickon steesit
- Aikatrendi on yleinen taustatekijä, joka selittää kahden muuttujan näennäisen riippuvuuden
- Ajassa itsensä kanssa korreloituneita muuttujia tulee syvällisemmin analysoida aikasarja- tai pitkittäistutkimusmenetelmillä
- Maailma on täynnä mielenkiintoisia tilastoja, mutta niitä on helppo ymmärtää väärin