
Ikääntymisen myötä olen tullut koko ajan laiskemmaksi etsimällä etsimään uusia bändejä kuuneltavaksi. Eräs syy, miksi tykkään Spotifyn musiikkipalvelusta on heidän ”Viikon suositukset” listansa. Tälle listalle valikoituu biisejä, joista saattaisin heidän algoritmiensa mukaan tykätä viime aikojen musiikinkuuntelun perusteella. Tämä on erittäin kätevä tapa löytää uusia itselleen iskeviä bändejä. Tälläkin hetkellä luukutan lupaavan kuuloista metalliorkesteria ”Fight the Fight”, mihin en ihan heti olisi törmännyt ilman Spotifya.
Dataa omista ennusteista
 ”Viikon suositukset” -listaa tulee kuunneltua usein taustamusiikkina ilman, että skippailisin yli biisejä, vaikka ne eivät maistu eli ovat ns. vikasuosituksia. En tiedä, käsitteleekö Spotifyn algoritmi loppuunkuunneltuja biisejä todellisina musiikkimakuani kuvaavana havaintona, vaikka ne tulisi soittoon sen oman suosituksen kautta. Tämän takia olen hieman vainoharhaisesti pitänyt taukoja huonosti osuneiden viikkojen jälkeen ja kuunnellut vain itse valitsemaa musiikkia, ettei algoritmi vaan alkaisi opettaman itseään omilla virheillään.
”Viikon suositukset” -listaa tulee kuunneltua usein taustamusiikkina ilman, että skippailisin yli biisejä, vaikka ne eivät maistu eli ovat ns. vikasuosituksia. En tiedä, käsitteleekö Spotifyn algoritmi loppuunkuunneltuja biisejä todellisina musiikkimakuani kuvaavana havaintona, vaikka ne tulisi soittoon sen oman suosituksen kautta. Tämän takia olen hieman vainoharhaisesti pitänyt taukoja huonosti osuneiden viikkojen jälkeen ja kuunnellut vain itse valitsemaa musiikkia, ettei algoritmi vaan alkaisi opettaman itseään omilla virheillään.
Mitä haittaa siitä sitten oikeasti olisi, mikäli joku algoritmi ei tunnista itsensä syöttämiä havaintoja? Tätä lähdetään nyt selvittämään asuntohinta-aineiston avulla.
Hinta-arviot algoritmilla
Siinä ei varmaan ole mitään yllättävää että iso osa pörssissä tehtävästä kaupankäynnistä tulee automaattisesti hinnoittelua suorittavien algoritmien toimesta. Sama ajatus asuntokaupassa tuntuu hieman etäisemmältä, mutta leikitellään vähän ajatuksella.
Olen ollut kehittämässä muutama vuosi sitten ASLA -asuntolaskuria, joka pyrkii antamaan kerrostaloasunnoille markkinahinta-arvioita julkisen datan perusteella. Asuntojen hinnat määräytyvät lukuisten ihmisten mieltymysten ja preferenssien perusteella. ASLAn taustalla oleva algoritmi pyrkii käytettävissä olevan datan avulla muuttamaan kaupankävijöiden keskimääräisiä mieltymyksiä matemaattisiksi kaavoiksi. Mitä tapahtuisi, jos osassa kaupoista normaali tinkimisprosessi jäisi pois ja sekä myyjä että ostaja luottavat ASLAn arvioon tehden kauppansa mukisematta kyseisillä arvioilla?
Seuraavassa olen simuloinut tällaista prosessia niin että vuodesta 2014 alkaen osassa todellisista asuntokaupoista hinta korvataankin ASLAn käyttämän algoritmin arviolla (korvattavat valitaan satunnaisesti) ja joka vuoden päätteeksi algoritmi kouluttaa itseään lisää uudella kertyneellä datalla. Aineistona käytetään Helsingin yksiöitä ja otoskoko-ongelmien välttämiseksi mukana on vain kymmenen kaupankäyntimäärältään suosituinta postinumeroaluetta.
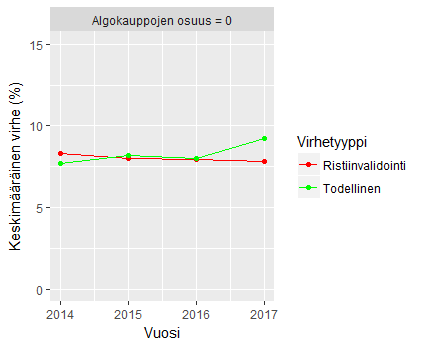 Kuvaajassa olevat viivat kuvaavat kolmea eri virheprosenttia vuosina 2014-2017:
Kuvaajassa olevat viivat kuvaavat kolmea eri virheprosenttia vuosina 2014-2017:
- Ristiinvalidointi (punainen): Etukäteisarvio algoritmin hinta-arvion ja todellisten hintojen keskimääräisestä prosentuaalisesta erosta. Ristiinvalidoinnin ideasta lisää tällä videolla.
- Todellinen (vihreä): Algoritmin hinta-arvioiden ja todellisten, ihmisten määrittelemien hintojen, keskimääräinen prosentuaalinen ero
- Näennäinen (sininen): Hinta-arvioiden ja havaittujen hintojen keskimääräinen prosentuaalinen ero, kun mukana on myös algoritmin avulla määritellyt kauppahinnat
Ensimmäisessä kuvaajassa (ylhäällä) kukaan kaupankävijä ei käytä ASLAa vaan kaikki myyntihinnat ovat aitoja ihmisten preferensseihin perustuvia hintoja. Sekä ennalta arvioidut että todellisuudessa kohdatut virheprosentit pyörivät lähellä toisiaan 8% – 9% välimaastossa.
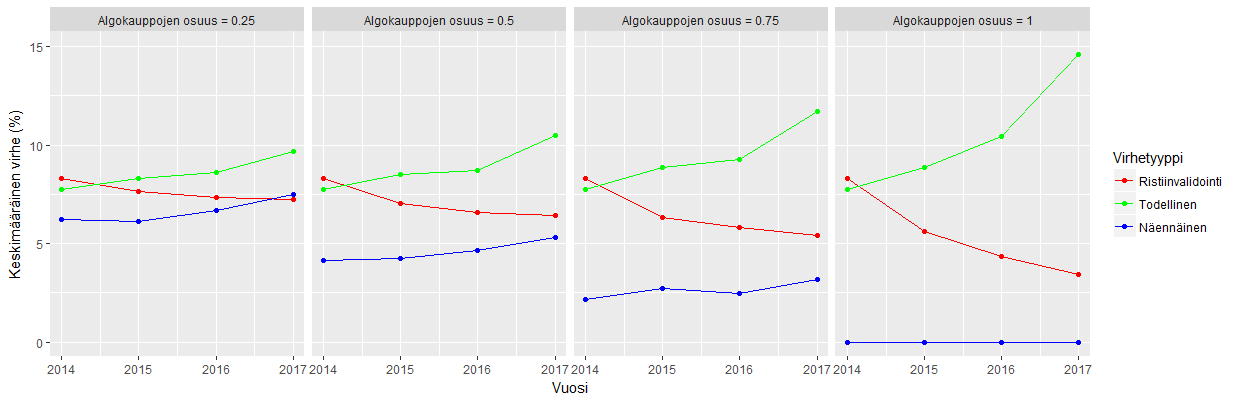 Seuraavissa kuvissa aina tietyn vuoden vuoden oikeita kauppahintoja korvataan ASLAn ennusteilla. Ensin satunnaisesti 25%, sitten puolet, sitten 75% ja viimeisessä kuvaajassa kaikki. Huomataan että ajan kuluessa algoritmin itsevarmuus kasvaa, eli punainen ristiinvalidointiin perustuvat virhearvioennusteet pienenevät. Mutta todellinen kyky arvioida ihmisten preferenssejä kuitenkin laskee, koska vihreä käyrä kasvaa kohti suurempia lukemia. Efekti on sitä selvempi, mitä isompi osuus kauppahinnoista tulee algoritmin perusteella. Ääritapauksessa oikealla, missä kaikki kauppahinnat tulevat suoraan algoritmista, havaitut ennustevirheet ovat nollassa (sininen käyrä), mutta kyky arvioida ihmisten preferenssejä (vihreä käyrä) on aivan jotain muuta.
Seuraavissa kuvissa aina tietyn vuoden vuoden oikeita kauppahintoja korvataan ASLAn ennusteilla. Ensin satunnaisesti 25%, sitten puolet, sitten 75% ja viimeisessä kuvaajassa kaikki. Huomataan että ajan kuluessa algoritmin itsevarmuus kasvaa, eli punainen ristiinvalidointiin perustuvat virhearvioennusteet pienenevät. Mutta todellinen kyky arvioida ihmisten preferenssejä kuitenkin laskee, koska vihreä käyrä kasvaa kohti suurempia lukemia. Efekti on sitä selvempi, mitä isompi osuus kauppahinnoista tulee algoritmin perusteella. Ääritapauksessa oikealla, missä kaikki kauppahinnat tulevat suoraan algoritmista, havaitut ennustevirheet ovat nollassa (sininen käyrä), mutta kyky arvioida ihmisten preferenssejä (vihreä käyrä) on aivan jotain muuta.
Omat ennusteet eivät ole aitoja havaintoja
Kun asuntoja hinnoitellaan suoraan algoritmin perusteella, alkaa algoritmin satunnaiset virheet toistumaan ja erityisesti se ei osaa sopeutua ajan tuomiin muutoksiin. Esimerkiksi algoritmi ei ymmärrä, että asuntojen hintoihin kohdistuu laskupainetta, mikäli korot tai kiinteistöverot nousevat äkillisesti. Nyt jos näitä muutoksia ei korjata aidolla uudella datalla, algoritmi alkaa irtaantumaan todellisista ihmisten preferensseistä.
ASLAa ei ole missään nimessä tarkoitettu automaattiseksi hinnoittelijaksi korvaamaan täysin kiinteistövälittäjiä vaan kauppaa käyvän ihmis-olion apuvälineeksi. Se antaa tukea erityisesti kokemattomalle kaupankävijälle uudella paikkakunnalla, mutta jättää huomioimatta monia tärkeitä asioita, kuten tehdyt taloyhtiöremontit ja tonttien omistusoikeudet. Algoritmi tehostaa ja tarkentaa ihmisen työtä tiivistämällä kaiken datassa olevan tiedon sekunnissa ilman että tarvitsee manuaalisesti (silmin selaimella tai Exceliä yötä myöden hakkaamalla) yrittää datasta ottaa tolkkua. Ihminen voi käyttää omat resurssinsa siihen, mitä kone ei osaa eli tässä tapauksessa esimerkiksi arvioida tulevia remontteja ja havainnoida esteettisiä kokemuksia paikan päällä.
Itse luotujen havaintojen siivoaminen
Palaten alkuperäiseen pohdintaan algoritmien omien havaintojen käyttämisessä sen opettamisessa, meillä on kädessä ongelma. Kuten asuntohintojen tapauksessa huomattiin, sitä mukaa kun itse luotua dataa kertyy lisää, algoritmin ”itseluottamus” kasvaa samalla kun todellinen performanssi heikkenee.
Spotifyn algoritmin on mahdollista (ja omasta vainoharhaisuudesta huolimatta näin mahdollisesti tekeekin) kehäpäätelmät välttää, koska jossain heidän tietokannassaan luulisi olevan tieto, valitsiko käyttäjä jonkin kappaleen soimaan omatoimisesti vai tuliko se suosituksen kautta automaattisesti. Jälkimmäiset tulee putsata pois datasta, jolla algoritmia jatkokoulutetaan. Asuntohinta-esimerkki on kinkkisempi, koska emme tiedä, onko joku tietty kaupankävijä käyttänyt algoritmia vai ei.
Mitä tulee ASLAn tulevaisuuteen, herää kysymys: ”Kannattaako laskurin näkyvyyttä yrittää lisätä, jos riskinä on, että siitä tulee sitä epätarkempi, mitä useampi sitä käyttää?” Kaupallinen käyttökin on kielletty taustalla käytettävän datan käyttöehtojen takia.
Statistickon steesit:
- Algoritmin kouluttaminen sen itse luomalla datalla on kehäpäätelmä
- Ajan myötä taustaolosuhteiden muuttuessa algoritmit tuppaavan irtaantumaan todellisuudesta, ellei niitä kouluteta uusilla, aidoilla havainnoilla
- Omien ennusteiden käyttäminen opetusdatana vielä huonontaa tilannetta antamalla valheellisen illuusion tarkentuvista ennusteista