
Kirjoitus on julkaistu myös Louhia-blogissa 21.10.2014.
Korrelaatiokerroin on eräs mittari kahden muuttujan välisen yhteyden mittaamiseen. Mikäli termi ei ole ennestään tuttu, sen ideaan voi tutustua esim. täällä. Sosiaalisessa mediassa on kiertänyt tällainen sivusto, jonne on listattu korrelaatiolla mitattuja yhteyksiä mitä eriskummallisimpien ilmiöiden välille. Mikä nämä selittää? Hukuttautuvatko ihmiset nähdessään Nicholas Cagen tähdittämän elokuvan vai onko taulukkolaskentaohjelma mennyt sekaisin?
Korrelaatioiden lähteet
Kahden ilmiön välinen korrelaation suuruus tilastoaineistossa voi johtua seuraavista neljästä asiasta tai jostain niiden yhdistelmästä.
1. Syy-seuraus suhde
Esim. kahvin juonti aiheuttaa verenpaineen kohoamista, mutta yhteys ei toimi toisinpäin. Korkea verenpaine ei yllytä juomaan lisää kahvia. Tällaista yhteyttä kutsutaan myös kausaaliteetiksi.

2. Molemminpuolinen riippuvuus
Esim. tietyn kenkämallin kysyntä ja tarjonta: kysynnän kasvaessa yritys alkaa valmistamaan kenkiä lisää ja tarjonta kasvaa. Toisaalta jos syystä tai toisesta kenkiä on valmistettu poikkeuksellisen paljon, yritys pyrkii tehostetulla markkinoinnilla tai alennuksilla lisäämään kysyntää.
3. Ilmiöt eivät suoraan riipu toisistaan, mutta molempiin vaikuttaa joku kolmas ilmiö
Esim. jo legendaarinen jäätelön syönti ja hukkumiskuolemat. Jäätelöä syömällä uimataidot eivät häviä vaan molempien taustalla on kolmas taustatekijä; lämpötila, mikä aiheuttaa samansuuntaista vaihtelua jäätelön syönnin ja hukkumiskuolemien välille.
4. Puhdas sattuma
Esittelemäni SoMe-artikkelin esimerkki, Nicholas Cagen leffaesiintymiset ja hukkumiset uima-altaaseen vuosina 1999-2009 saattaisi hyvinkin kuulua tähän kategoriaan. Ilmeistä on, että yhteys ei tule säilymään, mikäli seurantaa jatketaan vuodesta 2009 eteenpäin tarpeeksi pitkään.
Sattuman tuottamat korrelaatiot
Jos ihmiset eivät tarkoituksella hukuttaudu katsottuaan Cagen elokuvan tai juoksentele sähkölinjoihin mentyään naimisiin Alabamassa, niin mistä näitä merkillisiä korrelaatioita sitten tulee näin paljon? Tehdäänpä pieni kokeilu. Meillä on 7 muuttujaa, jotka voivat kuvata mitä numeroilla mitattavaa ilmiöitä tahansa, mutta niin etteivät ne todellisuudessa riipu millääan tavalla toisistaan. Nimetään muuttujat nyt X1, X2, …, X7. Arvoin kaikille näille muuttujille 12 (tyypillinen otoskoko SoMe-artikkelissa) satunnaislukuhavaintoa toisistaan riipumattomasti. Järkeenkäypää siis olisi, etteivät ne korreloisi keskenään ainakaan merkitsevästi. Tulokset näkyvät seuraavassa grafiikkamatriisissa.
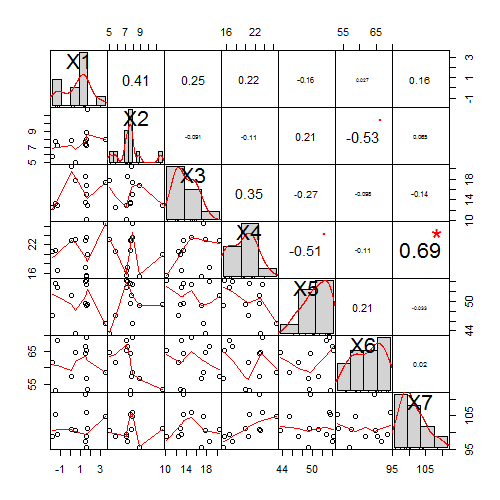
Vasemmasta ylänurkasta oikeaan alanurkkaan kulkevalla matriisin lävistäjällä on aina yksittäisen muuttujan arvottuja havaintoja kuvaava histogrammi. Vasemmalla alhaalla olevat sirontakuviot kuvaavat kahden muuttujan havaintoja yhtäaikaa niin että pystyakselilla on se muuttuja jonka rivillä ollaan ja vaaka-akselilla sarakemuuttuja.
Oikealla ylhäällä olevissa ruuduissa on kyseisellä rivillä ja sarakkella olevan muuttujan välinen korrelaatiokerroin. Luku on printattu sitä isommalla fontilla, mitä suurempi (itseisarvoltaan) korrelaatio on ja vieressä on punainen tähti osoittamassa mahdollista korrelaatiokertoimen tilastollista merkitsevyyttä. Punainen piste taas tarkoittaa, että korrelaatio on ”melkein merkitsevä” mutta ei aivan ylitä tieteellistä merkitsevyysrajaa.
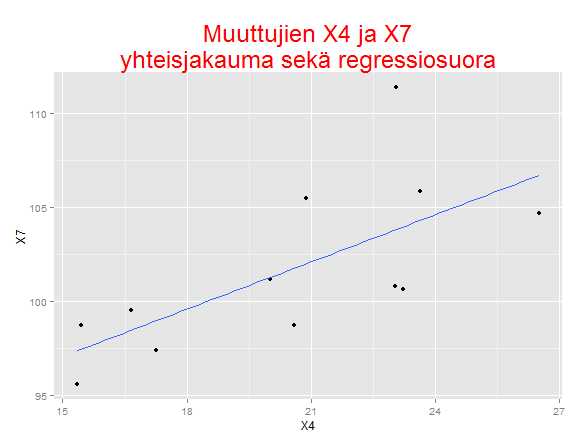 Nyt saatiin merkitsevä korrelaatiokerroin 0.69 muuttujien X4 ja X7 välille. Kun otetaan kyseiset muuttujat vielä lähempään tarkasteluun, huomataan että nouseva suora kuvaa hyvin muuttujien välistä yhteyttä aineistossa: X4:n ollessa suuri tuppaa X7 myös saamaan suuria arvoja. Nyt jos muuttujat sattuisivat olevaan vaikka ”Sabina Särkän lehtihaastattelujen lukumäärä yhden vuoden aikana” ja ”Matti Nykäsen vuoden pisimmän hypyn pituus”, SOME-hitti on valmis ja lööpit laulaa. Vain mielikuvitus on rajana keksiessä selityksiä tämän yhteyden välille.
Nyt saatiin merkitsevä korrelaatiokerroin 0.69 muuttujien X4 ja X7 välille. Kun otetaan kyseiset muuttujat vielä lähempään tarkasteluun, huomataan että nouseva suora kuvaa hyvin muuttujien välistä yhteyttä aineistossa: X4:n ollessa suuri tuppaa X7 myös saamaan suuria arvoja. Nyt jos muuttujat sattuisivat olevaan vaikka ”Sabina Särkän lehtihaastattelujen lukumäärä yhden vuoden aikana” ja ”Matti Nykäsen vuoden pisimmän hypyn pituus”, SOME-hitti on valmis ja lööpit laulaa. Vain mielikuvitus on rajana keksiessä selityksiä tämän yhteyden välille.
Todennäköisyyslaskenta on tutkijan paras kaveri
Vielä saattaa herätä kysymys, että huijasinko ja toistin arvontoja niin monta kertaa, kunnes tuli tällainen poikkeama. Todellisuudessa tässä ilmentymässä ei ole mitään poikkevaa, koska todennäköisyys saada sattumalta vähintään yksi merkitsevä korrelaatio, kun testataan 21 toisistaan riippumatonta muuttujaparia on n. 66%. Ei tarvita montakaan sataa muuttujaparivertailua, jotta saadaan kasaan SoMe-artikkelissa olevat 19 erikoista ”tilastollisesti merkitsevää” yhteyttä pelkästään sattumalta. Todellisessa tutkimuksessa on todennäköisyyslaskennan avulla syytä säätää korrelaatioiden hyväksymiskriteerejä sen mukaan, onko tärkeämpää löytää paljon potentiaalisia yhteyksiä vai välttää virheellisiä tulkintoja. Aina pitää olla hereillä, kun tekee suurista muuttujamääristä ”machine learning”-tyyppistä datan penkomista. Systemaattinen laskentaprosessi ilman todennäköisyysajattelua päätyy helposti itsensä harhaanjohtamiseen. Ja hauskoihin lööppeihin.
Statistickon steesit:
- Yksittäisestä aineistosta löytyy yllättävän suuria korrelaatioita sattumalta varsinkin kun havaintoja on vähän ja muuttujia paljon
- Tilastotieteen syvällisempi osaaminen auttaa välttämään riippuvuustutkimuksen sudenkuopat
[…] Vaikuttaa selkeältä: kun tuloerot kasvavat niin Puute kasvaa myös. Näiden välille laskettu korrelaatiokerroin (Spearmanin versio, koska yhteys ei ole lineaarinen) on 0.66 ja se on nyt tilastollisesti erittäin merkitsevä (totuuden mittareista tarkemmin tässä postauksessa). Voidaanko tästä vetää johtopäätös että suurista tuloeroista seuraa yhteiskuntaan vakavaa puutetta? Tässä vaiheessa on hyvä kerrata aiempi postaukseni korrelaatiotutkimuksista. […]
[…] niiden välille on mahdollista havaita keskinäistä riippuvuussuhdetta mittaavaa korrelaatiota. Aiemmassa blogikirjoituksessa havainnollistin kuinka korrelaatioita pompsahtelee esiin vain sattumalta kun tarpeeksi montaa eri […]