
Sijoittajamestari Ray Dalio kokosi elämässään oppimansa asiat teokseen Principles ja päätökseen tekoon liittyvä ensimmäinen periaate kuuluu näin:
”Recognize that 1) the biggest threat to good decision making is harmful emotions, and 2) decision making is a two-step process (first learning and then deciding).”
Ray Dalio
Datan analysointi tai datatieteily liityy nimenomaan ympäristöstä oppimiseen ilman tunteiden aiheuttamia vääristäviä tunteita niin että voitaisiin tehdä mahdollisimman valistuneita päätöksiä.
Kun tehdään liiketoimintaa tukevaa analyysiä, datan analysointi jaetaan tyypillisesti neljään alalajiin riippuen, mitä työllä tavoitellaan. Eri konsultit voivat järjestellä ne hieman eri tavoilla, mutta itse mielelläni järjestäen ne seuraavasti analyyttisen haastavuuden mukaan helpoimmasta vaikeimpaan:
- Kuvaileva analytiikka (Mitä tapahtui?)
- Ennakoiva analytiikka (Mitä tulee tapahtumaan?)
- Diagnosoiva analytiikka (Miksi jotain tapahtui?)
- Ohjaileva analytiikka (Mitä kannattaisi tehdä?)
Kolme ensimmäistä liittyy oppimiseen ja viimeinen päätöksentekoon opitun pohjalta.
Hukkuvat jäätelönsyöjät
Avataan sitten näitä alalajeja esimerkin avulla. Hukkuvat jäätelönsyöjät on monelle jo liiankin tuttu esimerkki riippuvuussuhteista, mutta ratsastetaan nyt vielä kerran sillä, koska se kaikessa tomppeluudessaan kuitenkin hyvin demonstroi oleellisia pointteja.
Olkoon meillä toimeksiantona jäätelökioskiyrittäjän auttaminen ja myyntiä ilmiönä kuvaa seuraava graafi.

Graafissa olevien syy-seuraus-yhteyksien pohjalta olen nyt simuloinut 300 havaintoa, jonka kanssa seuraavissa esimerkeissä operoidaan.
Kuvaileva analytiikka
Kuvaileva analytiikka vastaa siis kysymykseen ”Mitä tapahtui?”. Vastaus löytyy raporteista, joissa on tilastollisista tunnuslukuja ja graafisia kuvioita. Yritysmaailmassa tätä analytiikan alalajia kutsutaan termillä Business Intelligence (BI). Meidän dataa 300 aiemmasta viikkohavainnosta kuvaavat esim. seuraavat tunnusluvut.
| TEMP (C) | SALES (EUR) | DROWNED | |
| Keskiarvo | 19.6 | 13035 | 1.15 |
| Keskihajonta | 5.34 | 1315 | 3.52 |
Lisäksi mielenkiinnon mukaan tunnuslukuja voisi vertailla eri ryhmien, esim. viikonpäivien tai jäätelömakujen, välillä.
Keski- ja hajontalukujen lisäksi havaintoja voi kuvata muuttujien välisillä korrelaatiokertoimilla ja graafisilla kuvaajilla. Seuraava graafi ei ole välttämättä kauneimmasta päästä, mutta minulle sen piirtäminen on osa perusprosessia uuteen aineistoon tutustuttaessa. Siinä on paljon informaatiota tiiviisti ilmaistuna ja sen saa tulostettua R-ohjelmistolla yhdellä komennolla.
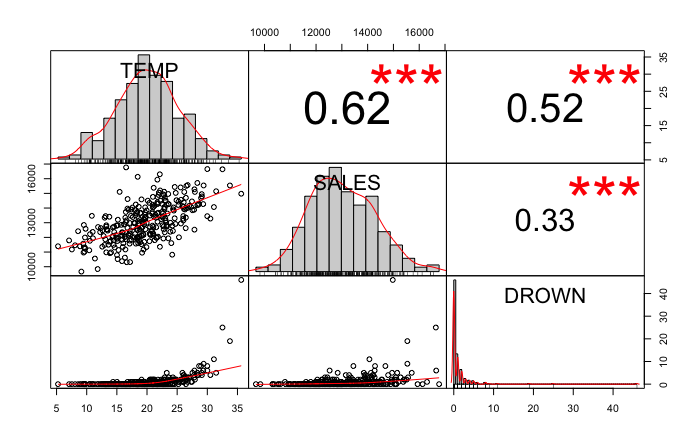
Kuvaajasta nähdään mm. seuraavaa:
- Lämpötilan ja myynnin havainnot ovat jakautuneet symmetrisesti keskiarvon ympärille ja muistuttaa normaalijakaumaa. Hukkumisten lukumäärän jakauma on vino.
- Kaikkien muuttujien väliset korrelaatiokertoimet (luvut oikealla ylhäällä) ovat positiivisia, joten muuttujilla on ollut taipumus saada isoja arvoja yhtäaikaa.
- Kaikki muuttujien väliset korrelaatiokertoimet ovat tilastollisesti erittäin merkitseviä (punaiset tähdet), joten ei ole uskottavaa että korrelaatiokertoimet poikkeavat nollasta vain sattumalta.
- Suora viiva kuvaa hyvin myynnin ja lämpötilan välistä yhteyttä. Hukkumisen ja muiden muuttujien välisen yhteyden kuvaamiseen suora viiva ei ole paras mahdollinen (kuviot vasemmalla alhaalla).
Kuvaileva analytiikka keskittyy kuvailemaan historian tapahtumia, mutta vastuu siitä, mitä tulee tapahtumaan tulevaisuudessa jää täysin raportin lukijalle.
Ennakoiva analytiikka
Vaikka historiakin on mielenkiintoista, vielä kiinnostavampaa liiketoiminnan kannalta on se mitä on odotettavissa tulevaisuudessa. Mennyt ei ole tae tulevasta, mutta historiaan perustuen voi tehdä valistuneita arvioita eri tulevaisuuden skenaarioiden todennäköisyyksistä.
Esimerkissämme mielenkiinnon kohteena on ennustaa tulevan viikon jäätelön myyntimäärä. Pelkään BI-raporttiin (kuvaileva analytiikka) perustuen paras arvaus olisi historiallinen keskiarvo 13035 euroa. Simuloin tässä 100 uutta havaintoa tulevista viikoista ja historialliseen keskiarvoon perustuva arvaus ei ole hassumpi: keskimäärin ennuste on 7.3% pielessä.
Olisimme voineet kuitenkin ottaa askel eteenpäin ennakoivan analytiikan puolelle ja muodostaa regressiomalli, jossa hyödynnetään tietoa päivän lämpötilasta. Lämpötilan ja myynnin välinen korrelaatiokerroinhan oli varsin suuri, 0.62. Tällaisen mallin tarjoama paras arvaus seuraavan viikon myynnistä menee nyt uusilla havainnoilla keskimäärin 6.5% pieleen.
Vaikka hukkumisilla ei ole syy-seuraus-suhdetta myyntiin, ei sen hyödyntämiselle ennustamisessa ole estettä. Jos sen lisää toiseksi selittäjäksi samaan regressiomalliin lämpötilan kanssa ei siitä iloa kuitenkaan ole, koska lämpötila jo yksinään selittää hukkumisten ja myynnin välisen yhteyden. Mutta mikäli vahingossa olisimme hukanneet historian lämpötilahavainnot, olisi hukkumiskuolemat hyvä apumuuttuja. Pelkästään edellisen viikon hukkumisiin perustuvat ennusteet ovat tässä tapauksessa 6.7% pielessä. Lopuksi vielä yhteenveto, kuinka tarkasti saatiin 100 uutta myyntihavaintoa ennustetttua.
| Ennustaja | Keskimääräinen virhe |
| Oma historia | 7.33% |
| Lämpötila | 6.45% |
| Hukkumiset | 6.73% |
| Lämpötila+Hukkumiset | 6.43% |
Regressiomallien lisäksi muita ennustamisen työkaluja ovat aikasarja-analyysi silloin kun kiinnitetään erityistä huomiota ajassa systemaattisesti toistuviin kuvioihin. Sitten kun käsillä on ajassa stabiili ilmiö, mutta paljon potentiaalisia selittäjiä sekä paljon dataa, arvoon arvaamattomaan nousevat erilaiset koneoppimisalgoritmit kuten neuroverkot tai päätöspuut. Mikäli useiden potentiaalisten selittäjien lisäksi meillä on hieman ymmärrystä näiden selittäjien keskinäisistä riippuuvuussuhteista, voidaan dataa ja asiantuntemusta yhdistää Bayes-verkkojen avulla tai simuloimalla maailman menoa ymmärryksemme rajoissa.
Käyttipä mitä tahansa näistä ennustusmenetelmistä tai jotain niiden yhdistelmää, meillä on kaksi ikävää kiusaa:
- Ylisovittaminen: tietämättämme yritämme tulevaisuutta ennustaa sellaisilla historiallisilla piirteillä, jotka ovat toteutuneet aiemmin vain sattumalta eivätkä kuvaa ilmiötä tulevaisuudessa. Tätä ongelmaa olen ruotinut aiemmin tässä kirjoituksessa.
- Pysyvät muutokset muuttujissa, joita ei olla aiemmin mitattu. Esimerkiksi lakimuutokset voivat ohjata ihmisiä käyttäytymään tulevaisuudessa eri tavalla kuin mihin aiemmin olemme tottuneet. Tätä ongelmaa olen käsitellyt tarkemmin tässä kirjoituksessa.
Kiitos mm. edellä mainittujen haasteiden ennakoivassa analytiikassa vaaditaan jo huomattavasti korkeamman tason koulutusta kuin kuvailevassa analytiikassa.
Diagnosoiva analytiikka
Diagnosoivalla analytiikalla pyritään löytämään asioiden välisiä syy-seuraus-yhteyksiä. Tieteellisen uteliaisuuden lisäksi liiketoiminnan kannalta kiinnostavaa voisi olla selvittää, mitä asioita muuttamalla saisimme myyntiä kasvatettua. Ennakoivan analytiikan maailmassa korrelaatiokertoimet antoivat hyviä vinkkejä, mitä muuttujia voisimme hyödyntää ennustamisessa. Kun tavoitteena on puuttua itse peliin asioiden muuttamiseksi, vain korrelaatioita tuijottamalla voisimme päätyä raportoimaan jäätelöyrittäjälle: ”Myynnin edistämiseksi kannattaa alkaa hukuttamaan ihmisiä”. Tämähän ei alkuunkaan pidä paikkansa niinkuin kohta tullaan näkemään.

Varmin tapa syy-seuraus eli kausaaliyhteyden selvittämiseksi on tehdä satunnaisettu koe riittävällä määrällä toistoja. Näistä klassinen esimerkki on antaa satunnaisesti toisille koehenkilöille oikeaa lääkettä ja toisille koehenkilöille lumelääkettä. Vaikutuksia vertailemalla voidaan saada selville, onko lääkkeessä oikeasti tehoa. Modernimpi esimerkki on verkkokaupan käyttöliittymän A/B-testaus, jossa satunnaisesti toisille asiakkaille nettisivulle näytetään punainen nappi ja toisille sininen nappi ja vertaillaan vaikuttaako napin väri sen klikkausten määrään.
Mikäli satunnaistetut kokeet eivät ole mahdollisia, voidaan yrittää metsästää luonnollisia kokeita. Esimerkiksi voidaan ottaa seurantaan henkilöt, jotka ovat juuri ja juuri päässeet läpi lääkiksen pääsykokeista ja vertailla tätä joukkoa niihin jotka jäivät niukasti ulos lääkiksestä. Voidaan olettaa että pienet erot pääsykokeen pistemäärissä jouhtuvat suurelta osin satunnaistekijöistä ja näin ollen on luotettavaa tehdä päätelmiä lääkiksen kausaalivaikutuksista loppuelämän onnellisuuteen.
Viimeisimpien vuosikymmenien aikana on erityisesti Judea Pearlin johdolla kehitetty kausaalimalleja, jotka auttavat tekemään kausaalipäätelmiä myös silloin kun käytössä havaittua dataa, mutta ei voida tehdä satunnaistettuja kokeita. Niissä aluksi pitää pystyä aiempiin tutkimuksiin perustuen rakentamaan graafi, josta näkee mitkä muuttujat vaikuttavat mielenkiinnon kohteina oleviin muuttujiin. Mikäli tärkeimmät näistä taustamuuttujista on mitattu, kausaalipäätelmät voivat olla mahdollisia.
Meidän kolmen muutttujan tapauksessa ilmiötä kuvaava graafi on esitelty kirjoituksen alussa. Tässä hyvin yksinkertaisessa maailmassa pystymme tutkimaan hukkumisten kausaalityhteyttä myyntiin. Kun laitamme sekä lämpötilan, että hukkumiset samaan regressiomalliin selittämään myyntiä, hukkumisella ei ole mitään selitysvoimaa, koska lämpötila on kaiken juurisyy. Näin ollen data näyttää, että ihmisiä on aivan turha alkaa hukuttamaan myynnin edistämiseksi.
Monimutkaisempien ilmiöiden tutkiminen kausaalimalleihin tukeutuen on itselläni vielä vaiheessa, joten ei kannata puhua tässä siitä sen enempää. Silti osa omaa analyysiprosessia on hahmotella graafiksi erilaisia potentiaalisia taustalla lymyileviä syy-seuraus-yhteyksiä, joita voi sitten asiaan paremmin vihkiytyneet haastaa. Mikäli mielenkiinto kausaalimalleihin heräsi, kannattaa aloittaa Judea Pearlin tietokirjasta ”The book of why”, josta Kimmo Pietiläinen on tehnyt myös suomenkielisen käännöksen: ”Miksi – syyn ja seurauksen uusi tiede”.
Ohjaileva analytiikka
Ohjaileva analytiikka on tässä lajittelussa laitettu viimeiseksi, koska pohjalla pitää olla alemman tason analytiikkaa päätöksenteon tueksi. Täältä huipulta kannattaa kuitenkin aina aloittaa pohtimalla, mitä halutaan tehdä. Mihin liittyviä päätöksiä analytiikalla halutaan parantaa? Esimerkkejä:
- Halutaan kehittää jäätelönmyynnin logistiikkaa: miten paljon mitäkin makua pitäisi toimittaa kioskille, että asiakkaat saavat mitä haluavat, mutta jäätelöä ei tarvitsisi kohtuuttomia määriä pakastimessa varastoida. – > Ratkaisu: Päätöksenteon tueksi tarvitsemme ennakoivaa analytiikkaa, jolla arvioidaan kuinka paljon mitäkin makua menee ensi viikolla.
- Halutaan lisätä jäätelön kysyntää. -> Ratkaisu: Diagnosoiva analytiikka. Johtopäätös on se, että korkeammat lämpötilat johtaisivat korkeampaan myyntiin. Mutta koska kaikki säiden hallitsemiseen kykenevät tahot ovat niin kallispalkkaisia, ei tällaista hanketta kannata toteuttaa. Laitetaan resurssit muun toiminnan kehittämiseen.
Kun pohjalla on riittävästi oppia analytiikan alemmilta tasoilta, ohjaileva analytiikka on pääasiassa erilaisia optimointialgoritmeja. Lisäksi on olemassa itseoppivia päätöksentekoalgoritmeja, jotka päivittävät omaa ymmärrystä aina päätöksestä tulleen palautteen perusteella.
Päätöksenteon optimointi on liian laaja aihe alkaa tässä syvemmin käsiteltäväksi, mutta se vaanii kaiken liiketoiminta-analytiikan taustalla. Ennen hosumista liian pitkälle datan kanssa, olisi hyvä ymmärtää mitä päätöksiä halutaan parantaa. Se mahdollistaa, että analytiikan alimmalta portaalta ponnistaessa edetään oikeaan suuntaan. Toisinaan matkalla opitaan jotain uutta, jonka vuoksi kurssia joudutaan kääntämään. Tämä tekee seikkailusta kuin seikkailusta entistä jännempää.
Lopputurinat
Dataan pohjautuvalla analytiikalla on useita eri tasoja ja niiden sisällä eri etenemispolkuja. Jotta varmistetaan datan penkomisen hyödyllisyys, aluksi pitäisi kirkastaa, mitkä päätöksentekoprosessit yrityksessä kaipaavat hiomista. Sitten valitaan sellainen polku, jota olemassa olevan datan pohjalta on mahdollista edetä. Lopulta päätöksenteko on kaksivaiheista: ensin opitaan, sitten päätetään.



 .
. .
.






