Otetaan heti alkuun pieni pähkinä, joka on hieman muokaten kopioitu Nassim Talebin kirjasta ”Fooled by randomness”.
Kuvitellaan tauti, jota sairastaa yksi tuhannesta suomalaisesta 40 vuotiaasta miehestä. Jarkko menee 40-vuotispäivän kunniaksi lääkärille rutiininomaiseen terveystarkastukseen ja lääkäri suorittaa verikokeen taudin testaamiseksi. Kokeesta tiedetään, että oikeasti sairaiden lisäksi se antaa positiivisen tuloksen 5% todennäköisyydellä silloin kun potilas on terve.
Jarkko sai kokeesta positiivisen tuloksen. Mikä on todennäköisyys, että Jarkolla on kyseinen tauti?
Mieti hetki vastausta, ennen kuin jatkat eteenpäin.
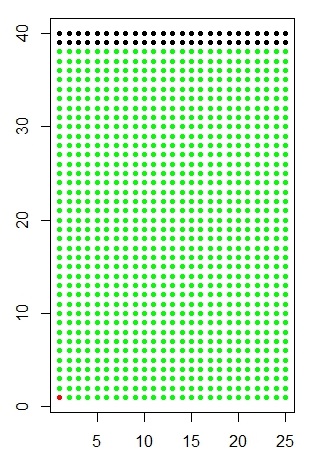 Vastasitko 95%? Ei se mitään, niin vastaa moni muukin pätevä kaveri. Mutta oikea vastaus on n. 2%. Pieleen menee yleensä siinä, että ennakkotieto ”yleinen sairastuneisuus 1/1000” jää huomiotta. Asian hahmottamiseksi vieressä on laatikko, jossa pallerot kuvaavat tyypillistä 1000 hengen otosta 40-vuotiaista miehistä. Punaisella värjätty alanurkan pallero on se epäonninen, joka sairastaa tautia. Jäljelle jäävistä 999 terveestä henkilöstä 0.05 * 999, eli noin 50 henkeä taas ovat sellaisia, jotka saavat verikokeesta virheellisen positiivisen tuloksen. Näitä ovat mustat pallerot ylhäällä. Pähkinän oikea vastaus tulee jakolaskusta 1/(1 + 50).
Vastasitko 95%? Ei se mitään, niin vastaa moni muukin pätevä kaveri. Mutta oikea vastaus on n. 2%. Pieleen menee yleensä siinä, että ennakkotieto ”yleinen sairastuneisuus 1/1000” jää huomiotta. Asian hahmottamiseksi vieressä on laatikko, jossa pallerot kuvaavat tyypillistä 1000 hengen otosta 40-vuotiaista miehistä. Punaisella värjätty alanurkan pallero on se epäonninen, joka sairastaa tautia. Jäljelle jäävistä 999 terveestä henkilöstä 0.05 * 999, eli noin 50 henkeä taas ovat sellaisia, jotka saavat verikokeesta virheellisen positiivisen tuloksen. Näitä ovat mustat pallerot ylhäällä. Pähkinän oikea vastaus tulee jakolaskusta 1/(1 + 50).
Edellinen verikoe on esimerkki tilanteesta, jossa totuuden etsimiseksi on kehitetty testi, jonka lopputulokseen liittyy epävarmuutta. Myös tieteen tekeminen on jatkuvaa painimista löydöksiin liittyvien epävarmuuksien kanssa. Esittelen seuraavaksi kolme mittaria, jotka auttavat tieteellisen löydöksen totuusarvon mittaamisessa.
Tilastollinen merkitsevyys (P-arvo)
P-arvo on tärkein ja tunnetuin mittari sille, kuinka uskottava tutkimustuloksemme on. Kyseessä on ehdollinen todennäköisyys: Todennäköisyys, että löydös ilmenee aineistossa sattumalta JOS se ei oikeasti pidä paikkaansa. Akateemisessa tutkimuksessa löydöstä yleensä pidetään tilastollisesti merkitsevänä, jos P-arvo on pienempi kuin 0.05. P-arvoa kuitenkin ylitulkitaan jatkuvasti samoin kuin ”Jarkon sairausdiagnoosi” -esimerkissä. P-arvo 0.05 EI nimittäin tarkoita välttämättä, että tutkimuslöydös olisi 95% todennäköisyydellä tosi.
Tilastollinen voimakkuus (Power)
Voimakkuus on ”Todennäköisyys, että tutkimusaineisto paljastaa etsimämme ilmiön JOS ilmiö on oikeasti olemassa.” Mediahuomiotakin saaneen Kimble-tutkimuksen tapauksessa: ”Todennäköisyys, että vastakkaisia silmälukuja tulee tilastollisesti merkitsevästi enemmän tutkimuksessamme, jos nopassa on oikeasti systematiikkaa.” Voimakkuuslaskelmia käytetään pääasiassa ennen tutkimusta selvittämään sopivaa otoskokoa tutkimukselle, mutta se on hyödyllinen tieto myös myöhemmin löydöksen totuusarvoa laskiessa.
Ennakkokäsitys ilmiöstä (Prioritieto)
P-arvo ja Power ovat siis ilmiön paljastumistodennäköisyyksiä tietyillä ehdoilla ja me haluaisime päästä käsiksi ilmiön olemassaolon todennäköisyyteen. Tämä onnistuu ottamalla huomioon ennakkokäsitys ilmiöstä ennen tutkimusaineiston keräämistä.
Esimerkiksi Kimble-tutkimuksessa ennakkokäsityksemme oli suurinpiirtein seuraavanlainen: ”Nuorisokodin peleissä ykkönen on tullut kuutosen jälkeeen silmiinpistävän usein. Kyse voi kuitenkin olla sattumasta ja siitä seuraavasta psykologisesta harhasta. Toisaalta systematiikat ovat mahdollisia, koska noppakupu on sen verran pieni. Noppa voisi olla kyseisellä tavalla epäsatunnainen ehkä 20% todenäköisyydellä, eli kerran viidestä.”
Tässä kohti huomataan, että peliä vuosikymmeniä hakanneella konkarilla ennakkokäsitys olla täysin erilainen. Joku aktiivipelaaja olisi saattanut nähdä asian seuraavasti: ”Vuosikymmenten kokemuksella olen hyvin varma ilmiön olemassaolosta. Väittäisin olevan sen tosi 90% todennäköisyydellä.” Ennakkokäsitys on usein hyvin subjektiivinen näkemys.
 Subjektiivisten näkemyksien suhteen ollaan ymmärrettävistä syistä varovaisia akateemisen tutkimuksen tilastoanalyysissä. Emme halua, että tieteen tulokset ovat liian riippuvaisia yksittäisen tutkijan subjektiivisesta näkemyksestä. Ainahan on olemassa riski, että ideologiset näkemykset tai henkilökohtaiset haaveet ohjaavat yksittäisen henkilön ennakkokäsitystä tiettyyn suuntaan.
Subjektiivisten näkemyksien suhteen ollaan ymmärrettävistä syistä varovaisia akateemisen tutkimuksen tilastoanalyysissä. Emme halua, että tieteen tulokset ovat liian riippuvaisia yksittäisen tutkijan subjektiivisesta näkemyksestä. Ainahan on olemassa riski, että ideologiset näkemykset tai henkilökohtaiset haaveet ohjaavat yksittäisen henkilön ennakkokäsitystä tiettyyn suuntaan.
Sen sijaan esim. yrityksen tehdessä tutkimusta vain oman liiketoimintansa päätöksenteon tueksi prioritietoa kannattaa hyödyntää, mikäli palkkalistoilta löytyy asiantuntija, joka osaa muuttaa näkemyksensä numeeriseen muotoon. Liiketoiminnassa taloudelliset intressit kannustavat kohti objektiivisuutta. Virheelliset johtopäätökset kun tuppaavat näkymään yrityksen tuloksessa.
Prioritodennäköisyyden ongelma on sen vaikea määrittäminen yksiselitteisen objektiivisesti. John Ioannidis käyttää artikkelissaan erästä objektiivista lähestymistapaa: selvitetään kaikki viimeaikojen oman tutkimusalan tutkimukset ja käytetään prioritodennäköisyytenä suhdetta, jolla aloitetut tutkimukset ovat lopulta johtaneet oikeaan uuteen löydökseen. Tämän asian selvittäminen ei kuitenkaan käy ihan sormia napsauttamalla.
Tutkimuslöydösten totuusarvot
Nyt meillä alkaa olla riittävästi työkaluja käydä käsiksi tutkittavan ilmiön olemassaolon todennäköisyyteen. Mietitään tyypillistä standardien mukaan suunniteltua tutkimusta. Mikäli matematiikka ei ole lähellä sydäntäsi voit jättää kaavat ja kreikkalaiset kirjaimet omaan arvoonsa. Tutkimuksen tilastollinen voimakkuus  on standardi 0.8 ja tilastollinen merkitsevyyskriteeri
on standardi 0.8 ja tilastollinen merkitsevyyskriteeri  on 0.05. Olkoon testattava hypoteesi
on 0.05. Olkoon testattava hypoteesi  aiemman Kimble-esimerkin tapainen, mikä voidaan olettaa ennakkokäsityksen mukaan todeksi 20% varmuudella. Nyt jos data kriteereillämme paljastaa ilmiön, sen todennäköisyys olemassaololle on 80%. Tämä saadaan laskettua Bayesin säännöstä johdetulla kaavalla (johdin sen tähän hätään itse, joten suhtautuminen varauksella):
aiemman Kimble-esimerkin tapainen, mikä voidaan olettaa ennakkokäsityksen mukaan todeksi 20% varmuudella. Nyt jos data kriteereillämme paljastaa ilmiön, sen todennäköisyys olemassaololle on 80%. Tämä saadaan laskettua Bayesin säännöstä johdetulla kaavalla (johdin sen tähän hätään itse, joten suhtautuminen varauksella):

Mietitään sitten vertailun vuoksi tutkimusta, jossa voimakkuus ja merkitsevyyskriteeri ovat edelleen samoja, mutta tarkoitus on testailla vähän kaikkea, jos satuttaisiin löytämään joitain tilastollisesti merkitseviä yhteyksiä. Meillä voisi olla vaikka pitkä lista erilaisista Kimble-pelaajien ominaisuuksista kätisyydestä hapenottokykyyn ja tutkimme, sattuisiko jollain niistä olemaan yhteyttä pelissä pärjäämiseen. Tällöin yksittäiseen testiin liittyvä prioritodennäköisyys ilmiön olemassaololle voisi olla luokkaa 1%. Nyt ylläolevalla kaavalla laskettu totuusarvo kyseiselle löydökselle romahtaa niinkin alas kuin 14%:iin.
Pieni prioritodennäköisyys romauttaa löydöksen totuusarvon, koska sattumalta tulevat löydökset dominoivat tilastollisesta merkitsevyydestä huolimatta. Näin kävi alun sairausdiagnoosipähkinässäkin. Lisäpähkinä pohdittavaksi: Matias saa saman diagnoosin kuin Jarkko, mutta hän tietää jo ennalta omaavansa geenit, jotka nostavat kyseisen sairauden puhkeamisen riskiä.
Käytännön prosessit
 Ennakkonäkemyksen kunnollinen hyödyntäminen on todellisuudessa vaikeaa, mutta tärkeintä tässä on huomata ero huolellisesti valitun hypoteesin tutkimisen ja ”vähän kaiken kokeilun”, (exploratiivisen tutkimuksen) välillä. Tässä vaiheessa moni voi huomata, että omiin tutkimuksiin/tietolähteisiin liittyy enemmän epävarmuutta, mitä on tullut ajatelleeksi. Niin kävi itsellenikin tätä kirjoittaessa. Tutkimuksen huolellisella suunnittelulla voi kuitenkin luottaa olevansa useammin oikeassa kuin väärässä, vaikkei tarkkoja prioritodennäköisyyksiä pystyisikään hahmottamaan.
Ennakkonäkemyksen kunnollinen hyödyntäminen on todellisuudessa vaikeaa, mutta tärkeintä tässä on huomata ero huolellisesti valitun hypoteesin tutkimisen ja ”vähän kaiken kokeilun”, (exploratiivisen tutkimuksen) välillä. Tässä vaiheessa moni voi huomata, että omiin tutkimuksiin/tietolähteisiin liittyy enemmän epävarmuutta, mitä on tullut ajatelleeksi. Niin kävi itsellenikin tätä kirjoittaessa. Tutkimuksen huolellisella suunnittelulla voi kuitenkin luottaa olevansa useammin oikeassa kuin väärässä, vaikkei tarkkoja prioritodennäköisyyksiä pystyisikään hahmottamaan.
Tutkimustiedon jatkokäsittelijän taas tulee muistaa olla kriittinen uuden mullistavan tiedon löytyessä. Oleellinen kysymys kuuluu: Kuinka tähän tulokseen päädyttiin? Onko kyseessä hakuammunnan tulos vai oliko alla jo muuta samaa ilmiötä tukevaa tutkimustietoa, jolle nyt haettiin varmistus?
Statistickon steesit:
- Tutkimuslöydöksen todenperäisyyden arviointiin tarvitaan tilastollisten mittareiden lisäksi prioritiedon hyödyntämistä
- Prioritiedon muuttaminen numeroiksi on usein hankalaa, mutta huolellisella tutkimussuunnittelulla voidaan kiertää tätä ongelmaa
- Kokeileva, exploratiivinen, tutkimus on tärkeää uusien tutkimussuuntien löytämiseen, mutta siitä on vielä pitkä matka totuudeksi julistamiseen